Introduction
이 섹션에서는 다양한 성능 관련 문제에 대해 설명합니다.
이 내용은 주로 프로그래머를 대상으로 합니다.
CPU 의존성
MagicaCloth는 Unity DOTS(Data-Oriented Technology Stack)를 사용합니다.
따라서 시뮬레이션 성능은 전적으로 CPU에 의존합니다.
반대로, GPU는 전혀 사용되지 않습니다.
또한, DOTS는 멀티스레딩을 지원하므로 CPU에 코어(스레드)가 많을수록 병렬로 실행되어 성능이 향상됩니다.
모바일 기기의 성능
그러나 Android/iPhone에서 사용할 때는 약간의 주의가 필요합니다.
모바일 기기의 CPU는 일반적으로 고성능 코어(big core)와 저전력 코어(small core)로 구성됩니다.
이를 Big-Little 구성이라고 합니다.
예를 들어, 8코어 CPU를 가진 단말기의 경우 대부분 Big4/Little4 등의 방식으로 나뉘어 있습니다.
이 경우, (4-4 코어)로 표현됩니다.
Unity는 DOTS를 Big 코어에서만 실행합니다.
따라서 위와 같은 기기의 경우, 8코어 중 오직 4개의 코어만 DOTS에 사용할 수 있습니다.
이 점을 유의하시기 바랍니다.
이 문제는 데스크톱 PC의 CPU에서는 발생하지 않습니다.
Check with Profiler
Unity의 프로파일러 기능을 사용하여 시뮬레이션 부하를 쉽게 확인할 수 있습니다.
프로파일러에서는 타임라인에 MagicaManager 블록으로 표시됩니다.
또한, Job 항목에서 멀티스레딩 상태를 확인할 수 있습니다.

Cloth Data의 생성 및 실행
MagicaCloth는 시뮬레이션을 수행하기 위해 다양한 데이터를 필요로 합니다.
이것을 Cloth Data라고 합니다.
Cloth Data는 요청에 따라 실행 시간에 동적으로 생성됩니다.
Cloth Data의 생성은 상당한 계산 작업을 필요로 하며, 보통 10ms에서 50ms 정도의 시간이 걸립니다.
이 생성 과정은 백그라운드 스레드에서 실행되므로 메인 스레드에는 영향을 거의 미치지 않습니다.
또한, 여러 개의 Cloth가 여러 스레드에서 생성되며 병렬로 실행됩니다.
하지만, 시뮬레이션은 이 Cloth Data가 완성될 때까지 기다려야 합니다.
이로 인해 캐릭터가 실제로 생성된 후 시뮬레이션이 시작되기까지 여러 프레임의 지연이 발생합니다.
Editor 실행 시 주의사항
MagicaCloth에서 사용하는 Burst와 JobSystem은 빌드할 때보다 에디터에서 실행할 때 더 많은 리소스를 소모합니다.
따라서 에디터에서 실행할 때의 프로파일러 내용은 빌드에서 실행할 때와 다를 수 있습니다.
이는 다음과 같은 요소들로 인해 발생합니다.
Burst JIT Compiler
Burst는 에디터에서만 런타임(Just-In-Time Compiler)에서 컴파일됩니다.
이 컴파일은 플레이가 시작된 후에 이루어지므로, MagicaCloth가 처음 사용될 때 컴파일 시간이 수백 ms 이상 걸릴 수 있습니다.
따라서 에디터 환경에서는 플레이 후 첫 번째 시뮬레이션이 시작되기 전에 상당한 지연이 발생합니다.
이 문제는 에디터 환경에서만 발생하며 빌드 시에는 발생하지 않습니다.
이 문제를 해결하려면 Enter Play Mode Options를 사용하십시오.
이 옵션은 PlayerSettings의 Editor 탭에 있습니다.
Enter Play Mode를 사용하면, 반복적인 플레이 작업 후에도 Burst가 다시 JIT 컴파일되지 않습니다.
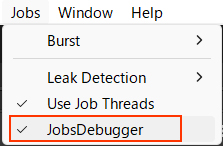
JobsDebugger 처리 부하
에디터에서는 JobsDebugger가 작업의 실행을 계속 모니터링합니다.
이로 인해 작업 실행 시간이 평소보다 길어지고, 작업 간에 부자연스러운 간격이 발생할 수 있습니다.
부하가 걱정되면 JobsDebugger를 끄는 것이 좋습니다.
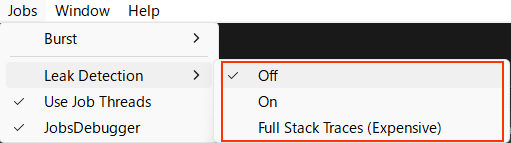
SafeCheck 처리 부하
마찬가지로, 에디터 환경에서는 Burst의 안전성도 모니터링됩니다.
이 부하는 어느 정도 발생하므로, 걱정된다면 두 가지 체크를 끄는 것이 좋습니다..
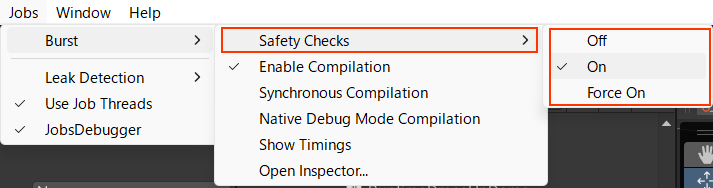
이 두 체크를 끄면 오류는 더 이상 보고되지 않습니다.
하지만 위에서 설명한 대로 JobDebugger와 SafeCheck를 끄면 Burst/Jobs 오류가 표시되지 않습니다.
따라서 MagicaCloth가 제대로 작동하지 않는다고 생각되면 모든 체크를 다시 켜고 오류를 확인해보세요
빌드에서 테스트 권장
위에서 언급한 바와 같이, 에디터에서 실행할 때는 여러 모니터링으로 인해 시뮬레이션 성능이 떨어집니다.
그러나 릴리스 빌드는 모든 모니터링을 제거합니다.
따라서 실제 기기에서 실제 성능을 확인하려면 빌드를 통해 테스트하는 것이 가장 좋습니다.
빌드 시 주의사항
Burst AOT 설정
빌드할 때 Burst를 활성화하는 것을 잊지 마세요.
이는 PlayerSettings에서 Burst AOT Settings에서 설정할 수 있습니다.
이 옵션을 체크 해제하면 빌드가 Burst가 비활성화된 상태로 빌드됩니다.
기본적으로는 활성화되어 있습니다.

IL2CPP 권장
빌드할 때 IL2CPP를 사용하는 것을 강력히 추천합니다.
이유는 C#의 처리 속도가 Mono에 비해 크게 향상되기 때문입니다.
처리 부하 목록
이 섹션에서는 MagicaCloth의 기능 중 가장 처리 집약적인 기능에 대해 설명합니다.
★이 많을수록 부하가 높아집니다.
천 데이터 생성 방법
| Runtime build (default) | ★★★ | 런타임 생성은 사용될 때 천 데이터를 그 자리에서 생성합니다. 이로 인해 초기화 시 부하가 증가합니다. 천 데이터는 백그라운드에서 생성되지만, 이 과정은 CPU를 소모합니다. |
| Pre-build | ★ | 프리 빌드는 천 데이터를 생성하여 에셋으로 만들어 편집 중에 미리 준비합니다. 이 방법은 초기화 부하를 크게 줄여줍니다. 또한, 백그라운드 처리도 없습니다. |
천 타입
| MeshCloth | ★★★★ | MeshCloth는 시뮬레이션 외에도 프록시 메쉬 스키닝과 렌더 메쉬에 다시 쓰는 작업이 포함되기 때문에 BoneCloth보다 훨씬 더 많은 부하를 요구합니다. 따라서 모바일 기기에서 사용할 때 성능에 주의해야 합니다. |
| BoneCloth | ★ | BoneCloth는 매우 가벼운 타입입니다. 대부분의 경우, 대량으로 사용해도 문제가 발생하지 않습니다. |
충돌 처리
| Self Collision | ★★★★★★★★★★ | Self-collision은 모든 기능 중에서 가장 눈에 띄고 처리 부하가 큰 과정입니다. 따라서 기본적으로 CPU 코어가 많은 데스크톱 PC에서 사용을 권장합니다. 모바일 기기에서 사용할 경우, 프록시 메쉬의 꼭지점 수를 가능한 한 줄이고 성능에 주의해야 합니다. |
| Mutual Collision | ★★★★★★ | Mutual collision은 다른 대상과의 충돌만 결정하기 때문에 self-collision보다는 부하가 약간 적습니다. 하지만 프로세스는 self-collision과 다를 바 없으므로 성능에 주의해야 합니다. |
| Edge Collision | ★★★★ | Edge collisions는 점 충돌보다 몇 배 더 많은 부하를 요구합니다. 점 충돌에서 문제가 발생할 때만 사용하도록 하세요. |
| Point Collision | ★★ | Point collisions는 다른 충돌 판별 방식에 비해 처리 부하가 훨씬 적습니다. |
| Backstop | ★ | Backstop은 계산이 적게 필요하기 때문에 가장 낮은 처리 부하를 가집니다. 따라서 걱정 없이 사용할 수 있습니다. |
시뮬레이션 주파수 및 최대 업데이트 수
MagicaCloth의 시뮬레이션은 자체적인 시간 관리 방식으로 인해 Unity의 프레임 업데이트와 다른 타이밍에 실행됩니다.
이것은 프레임 속도와 관계없이 일정한 간격으로 실행됩니다.

이 일정한 간격을 시뮬레이션 주파수라고 합니다.
예를 들어, 주파수가 90이면 시뮬레이션은 1초에 1/90초마다 업데이트됩니다.
이는 Unity의 물리 엔진 업데이트(FixedUpdate)와 프레임 업데이트 간의 관계와 같습니다.
MagicaCloth는 초기 주파수로 90을 설정해 두었습니다.
즉, 시뮬레이션은 1초에 90번 업데이트됩니다.
또한, 한 프레임에서 실행할 수 있는 최대 시뮬레이션 횟수가 설정되어 있습니다.
이것은 과도한 부하로 인해 시뮬레이션이 무한히 반복되지 않도록 방지하는 안전 기능입니다.
MagicaCloth는 초기값으로 3번이 설정되어 있습니다.
최대 횟수 때문에 시뮬레이션이 생략되면, 위치는 보간(interpolation) 함수로 보충됩니다.
이 보간 함수는 간단하고 정확도가 떨어집니다.
따라서 시뮬레이션이 생략되면 아티팩트가 발생할 수 있다는 점을 유의해야 합니다.
주파수와 성능
시뮬레이션 주파수는 성능과 밀접하게 관련이 있습니다.
주파수를 낮추면 시뮬레이션을 적게 실행하게 되어 성능이 향상됩니다.
하지만 주파수는 시뮬레이션 정확도에 큰 영향을 미칩니다.
따라서 주파수를 낮추면 시뮬레이션의 정확도도 낮아지게 됩니다.
주파수와 시뮬레이션 정확도 사이에는 트레이드오프가 있다는 점을 염두에 두어야 합니다.
주파수 및 최대 업데이트 수 변경
주파수와 최대 업데이트 횟수는 두 가지 방법으로 변경할 수 있습니다.
변경은 언제든지 가능합니다.
API
스크립트를 통해 API로 변경할 수 있습니다.
MagicaSettings
MagicaSettings라는 전용 컴포넌트를 제공하여 시스템의 상태를 변경할 수 있습니다.
이 컴포넌트를 사용하면 코딩 없이 주파수와 최대 업데이트 수를 변경할 수 있습니다.
설정 방법에 대해서는 MagicaSettings 문서를 참조하십시오.

주파수의 운영 효과
주파수를 변경하면 시뮬레이션 동작에 약간의 변화가 생깁니다.
예를 들어, 주파수를 90으로 설정한 상태에서 이동을 조정한 후, 주파수를 30이나 150으로 설정하면 이동이 달라지고 완전히 동일하지 않게 됩니다.
이는 주파수를 변경하면 파라미터의 효과에 약간의 차이가 발생하기 때문입니다.
따라서 주파수 변경은 파라미터 재조정이 필요할 수 있습니다.
설정예시
다음은 몇 가지 설정 예시입니다.
성능 우선 설정
성능이 중요하다면 주파수를 60으로 설정하고 최대 업데이트를 2로 설정해 보세요.
정확도는 조금 떨어지지만 성능이 향상됩니다.

고정 프레임 속도 설정
게임이 60fps와 같은 고정된 프레임 속도로 실행될 경우, 주파수를 이에 맞게 설정하는 것도 효과적입니다.
예를 들어, 주파수를 60으로 설정하고 최대 업데이트 횟수를 1로 제한하면 한 프레임의 부하가 안정화됩니다.

또한, 게임이 30fps로 실행된다면 주파수를 60으로 설정하고 최대 업데이트 횟수를 2로 설정하면 도움이 됩니다.
이렇게 하면 한 프레임에서 시뮬레이션이 두 번 업데이트되어 30fps에서도 주파수 60의 정확도를 확보할 수 있습니다.

성능 최우선 설정
성능을 최우선으로 한다면 주파수를 30으로 설정하고 최대 업데이트 횟수를 1로 설정해 보세요.
이 설정은 최대 성능을 발휘할 수 있습니다.
하지만 정확도가 크게 떨어지므로 매우 신중해야 합니다.
이 설정은 아티팩트보다 성능을 우선시하는 설정입니다.

컬링 시스템
컬링은 카메라에 표시되지 않거나 카메라에서 일정 거리 이상 떨어진 캐릭터들의 시뮬레이션을 중지시켜 성능을 향상시키는 기능입니다.

이 기능은 1인칭 FPS 게임이나 VR에서 성능을 크게 향상시킵니다.
컬링은 카메라 컬링과 거리 컬링의 두 가지 기능으로 구성됩니다.
https://www.youtube.com/watch?v=9uiXUocomVQ
https://www.youtube.com/watch?v=aP5ljTotmK4
자세한 내용은 컬링 시스템 문서를 참조하십시오.
캐릭터 배치
DOTS는 Transforms의 읽기 및 쓰기 작업에 멀티스레딩을 사용합니다.
하지만 이 혜택을 활용하려면 캐릭터 배치 방식에 주의해야 합니다.
DOTS에서는 Transform 처리가 계층 구조의 루트에 배치된 각 GameObject 그룹에 대해 멀티스레딩 방식으로 처리됩니다.
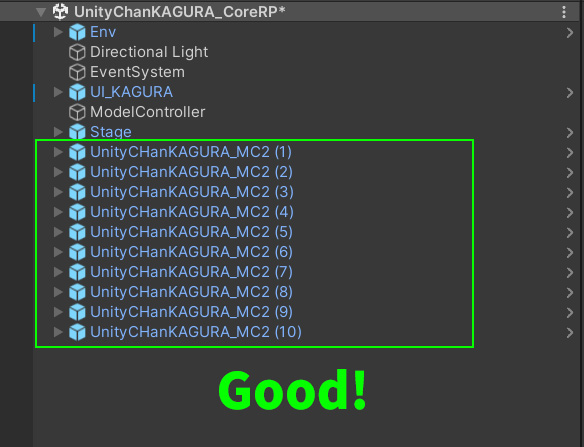
다음 예시에서, 모든 10개의 캐릭터가 루트에 배치되었으므로 각 캐릭터의 Transform 처리 과정은 여러 스레드에서 실행됩니다.
이것은 이상적인 배치입니다.
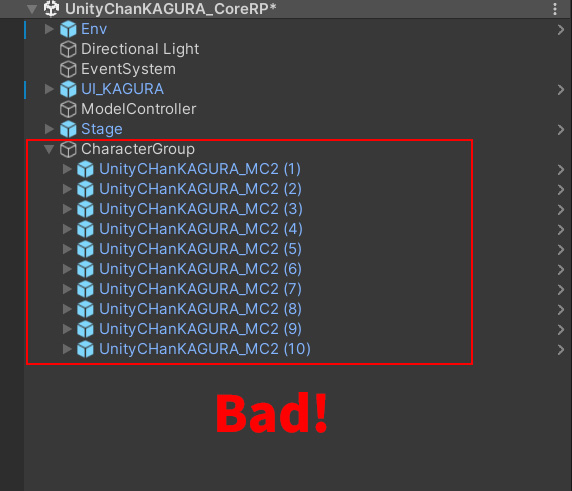
그러나 다음 예시에서는 모든 캐릭터가 "CharacterGroup" 객체의 자식으로 배치되어 있습니다.
이것은 매우 나쁜 예시로, Transform 처리가 전혀 멀티스레딩 방식으로 이루어지지 않습니다.
특히 많은 수의 캐릭터가 있을 경우 성능 저하가 두드러지게 나타날 수 있습니다.
시뮬레이션 작업
이 섹션에서는 천 시뮬레이션이 어떻게 수행되는지 설명합니다.
이 섹션은 시뮬레이션 프로세스가 최적화된 v2.14.0 이상 버전을 사용하고 있다고 가정합니다.
분할 작업
시뮬레이션 처리는 작업(job)이라는 처리 단위로 나누어져 실행됩니다.
이 작업들은 프로파일러에서 확인할 수 있습니다.
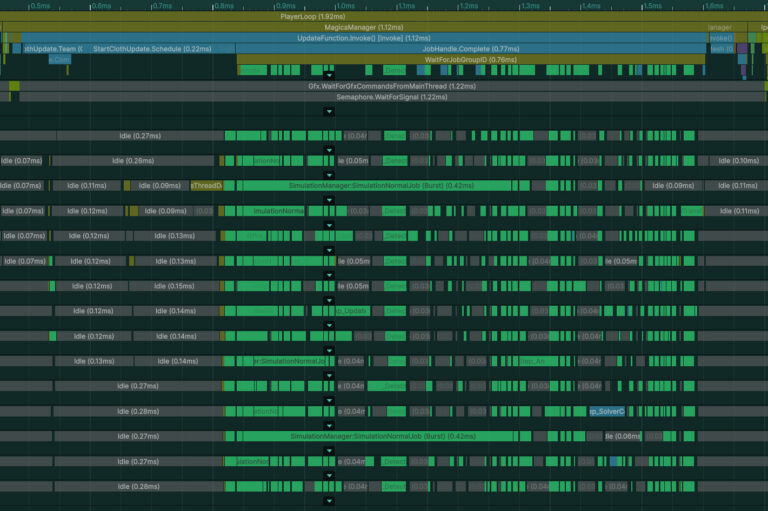
이미지에서 볼 수 있듯이 작업은 매우 작은 부분으로 나누어집니다.
이것은 각 처리 단계에서 데이터 동기화가 필요하기 때문입니다.
이 방법은 CPU 코어를 최대한 활용할 수 있다는 장점이 있지만, 작업 스케줄링 시간과 동기화 대기 시간 증가와 같은 단점도 있습니다.
배치 작업
따라서 v2.14.0부터는 작업을 나누지 않고 한 번에 처리하는 배치 작업을 추가하였습니다.
배치 작업에서는 하나의 MagicaCloth 컴포넌트 처리 작업이 하나의 작업으로 할당됩니다.
이렇게 하면 작업을 나누는 것에 비해 불필요한 동기화 시간이 제거되어 속도가 크게 향상됩니다.
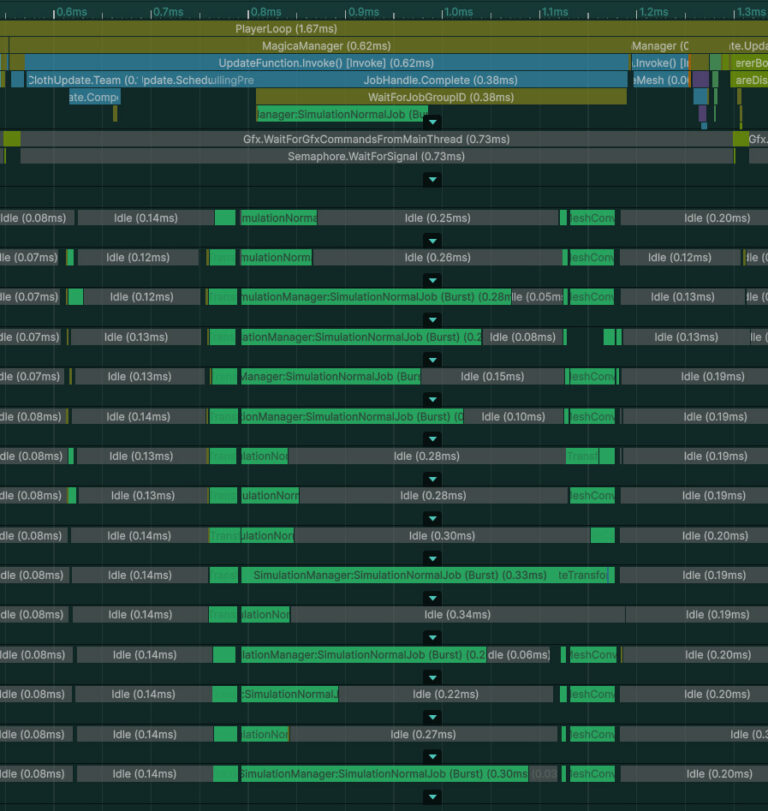
하지만 단점도 존재합니다.
배치 작업은 작업을 나누지 않기 때문에 스레드별로 처리를 분배할 수 없습니다.따라서 처리 시간이 무겁게 드는 MagicaCloth 컴포넌트가 하나 있을 경우, 전체 처리 시간이 연장될 수 있습니다.

다음과 같이, 무거운 작업이 처리되는 동안 다른 CPU 코어는 완전히 유휴 상태가 됩니다.
이로 인해 CPU는 매우 비효율적이며, 작업이 분리된 작업으로 처리될 때보다 더 많은 시간이 소요됩니다.
분할 작업과 배치 작업 함께 사용하기
이 문제를 해결하기 위해, 우리는 경량 컴포넌트는 배치 작업으로 처리하고, 무거운 컴포넌트는 분할 작업으로 처리하는 하이브리드 시스템을 구현했습니다.
이렇게 하면 CPU 낭비를 없애고 코어를 최대한 활용할 수 있습니다.
배치 작업과 분할 작업은 병렬로 실행됩니다.
분할 작업은 다음 두 가지 조건에서 적용됩니다:
- 프록시 메쉬의 꼭지점 수가 300개 이상인 경우
- Self-collision 또는 Mutual collision을 사용하는 경우
이 조건 중 하나라도 만족하면 분할 작업이 사용됩니다.
프록시 메쉬의 꼭지점 수는 인스펙터에서 확인할 수 있습니다.

분할 작업 임계값 변경
분할 작업의 조건은 프록시 메쉬의 꼭지점 수가 300개 이상이어야 하지만, 이 기준은 변경할 수 있습니다.
이를 변경하는 두 가지 방법은 다음과 같습니다:
- MagicaSettings
코딩 없이 MagicaSettings 컴포넌트를 설치하여 변경할 수 있습니다.
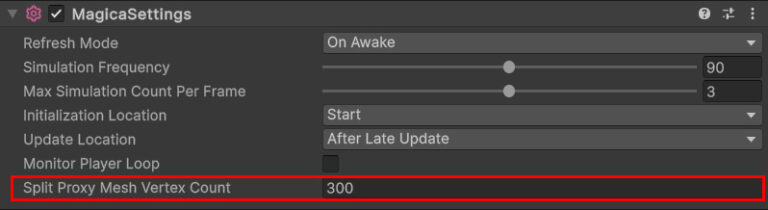
- API
SetSplitProxyMeshVertexCount 메서드를 사용하여 변경할 수 있습니다.
이 변경은 런타임 중 언제든지 할 수 있으므로, 최대 효율성을 원한다면 플랫폼에 따라 임계값을 조정하는 것을 고려하세요.
기타
에디터 환경에서의 극단적인 성능 저하
지금까지 최종 사용자들로부터 에디터 환경에서 실행 시 성능이 매우 낮다는 보고를 받았습니다.
로드가 빌드할 때보다 수십 배 더 높은 것으로 나타났습니다.
하지만 이 문제는 재현되지 않으며, 일부 PC 환경에서만 발생하는 것으로 알려져 있습니다.
이 상황을 겪으셨다면, 프로젝트의 Library 폴더를 아래와 같이 삭제해 보세요:
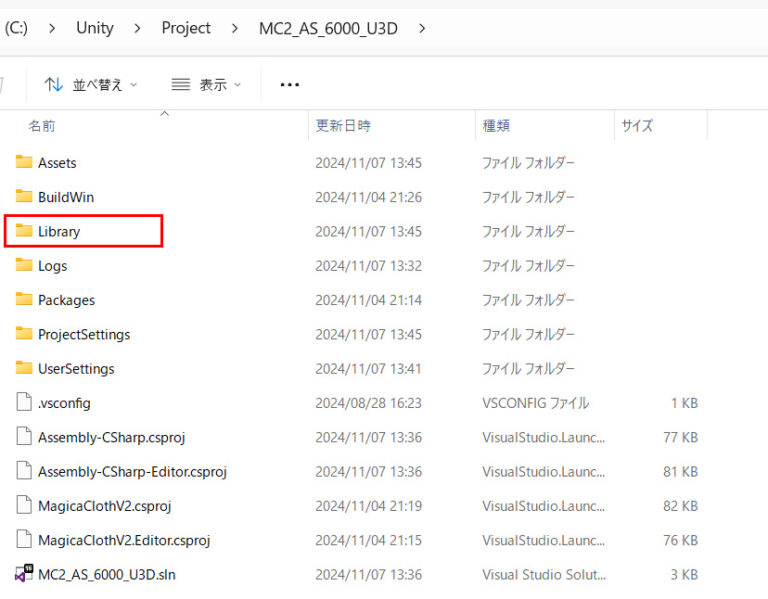
일부 사용자들은 이 방법으로 문제를 해결했다고 보고했습니다.
Library 폴더는 프로젝트의 작업 데이터를 저장하며, 삭제하면 자동으로 다시 빌드됩니다.
하지만 Library 폴더를 삭제하기 전에 다음 단계를 따르세요:
- Unity 에디터 종료
- 프로젝트 백업
- Library 폴더 삭제
- Unity 에디터 재시작
'유니티 에셋 > Magica Cloth 2' 카테고리의 다른 글
| 의상 변경(Dress-up) 프로세스 (0) | 2025.03.04 |
|---|---|
| 스케일 변경 (0) | 2025.03.04 |
| 런타임 변경사항 (0) | 2025.03.04 |
| 런타임 구성 (0) | 2025.03.04 |
| 캐릭터 인스턴스화 (Character Instantiation) (0) | 2025.03.02 |